Deep Radial-Basis Value Functions for Continuous Control
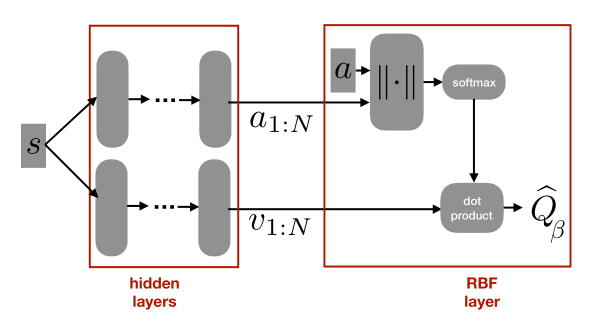 RBFDQN architecture
RBFDQN architecture
Abstract
A core operation in reinforcement learning (RL) is finding an action that is optimal with respect to a learned value function. This operation is often challenging when the learned value function takes continuous actions as input. We introduce deep radial-basis value functions (RBVFs): value functions learned using a deep network with a radial-basis function (RBF) output layer. We show that the maximum action-value with respect to a deep RBVF can be easily approximated up to any desired accuracy. Moreover, deep RBVFs can represent any true value function owing to their support for universal function approximation. We show that deep RBVFs facilitate the use of value-function-only algorithms in continuous control, and can serve as the critic in actor-critic algorithms. We extend the standard DQN algorithm to continuous control by endowing the agent with a deep RBVF, and show that it significantly outperforms value-function-only baselines and is competitive with state-of-the-art actor-critic algorithms. Together, these results reinvigorate radial-basis deep RL.